Benchmarking Visual Temporal Progress for Data Curation
Data scarcity remains one of the most limiting factors in driving progress in robotics. While the volume of available robotics datasets has grown exponentially, curating high-quality data from these collections remains a significant challenge. OpenGVL introduces a comprehensive benchmark for estimating task progress across diverse manipulation tasks involving both robotic and human embodiments, enabling automated data curation and filtering at scale.
Temporal Progress and Reward Models
Estimating temporal progress within a trajectory is fundamental to assessing data quality in robotics datasets. Given a trajectory \(\tau\), the objective is to assign scalar values reflecting how well the trajectory achieves its intended goal. Formally, this is captured by the value function:
$$V(\tau) = \mathbb{E}\left[\sum_{t=1}^{T} \gamma^{t-1} r_t \;\middle|\; \tau\right]$$where \(r_t\) represents the task success signal at each timestep and \(\gamma\) is a discount factor. In practice, ground-truth reward signals are rarely available, making it necessary to rely on learned or heuristic-based progress estimators. Vision-language models (VLMs) offer a promising avenue for this purpose, as they can leverage broad visual and semantic understanding to predict task completion from raw image observations without task-specific reward engineering.
Generative Value Learning
Generative Value Learning (GVL) is the core methodology underpinning OpenGVL. The approach leverages the knowledge embedded in pretrained vision-language models to predict task progression directly from visual observations. Given a set of shuffled frames sampled from a trajectory, a VLM is prompted to assign a completion percentage to each frame, reflecting how far the task has progressed at that point in time.
The quality of these predictions is measured using the Value-Order Correlation (VOC) metric, which computes the Spearman rank correlation between the predicted completion values \(\hat{v}_1, \dots, \hat{v}_N\) and the true temporal ordering of frames \(1, \dots, N\):
$$\text{VOC} = 1 - \frac{6 \sum_{i=1}^{N} d_i^2}{N(N^2 - 1)}$$where \(d_i\) is the difference between the predicted rank and the true temporal rank of frame \(i\). VOC ranges from \(-1\) (perfect inverse correlation) to \(+1\) (perfect temporal alignment). A high VOC indicates that the model can correctly distinguish early-stage frames from late-stage frames, even when the images are presented in randomised order. The benchmark evaluates models under two conditioning regimes: zero-shot, where the model receives only the shuffled evaluation frames and a task description, and two-shot, where two additional ordered context episodes with known progress labels are provided as reference.
Closed vs Open Source Models
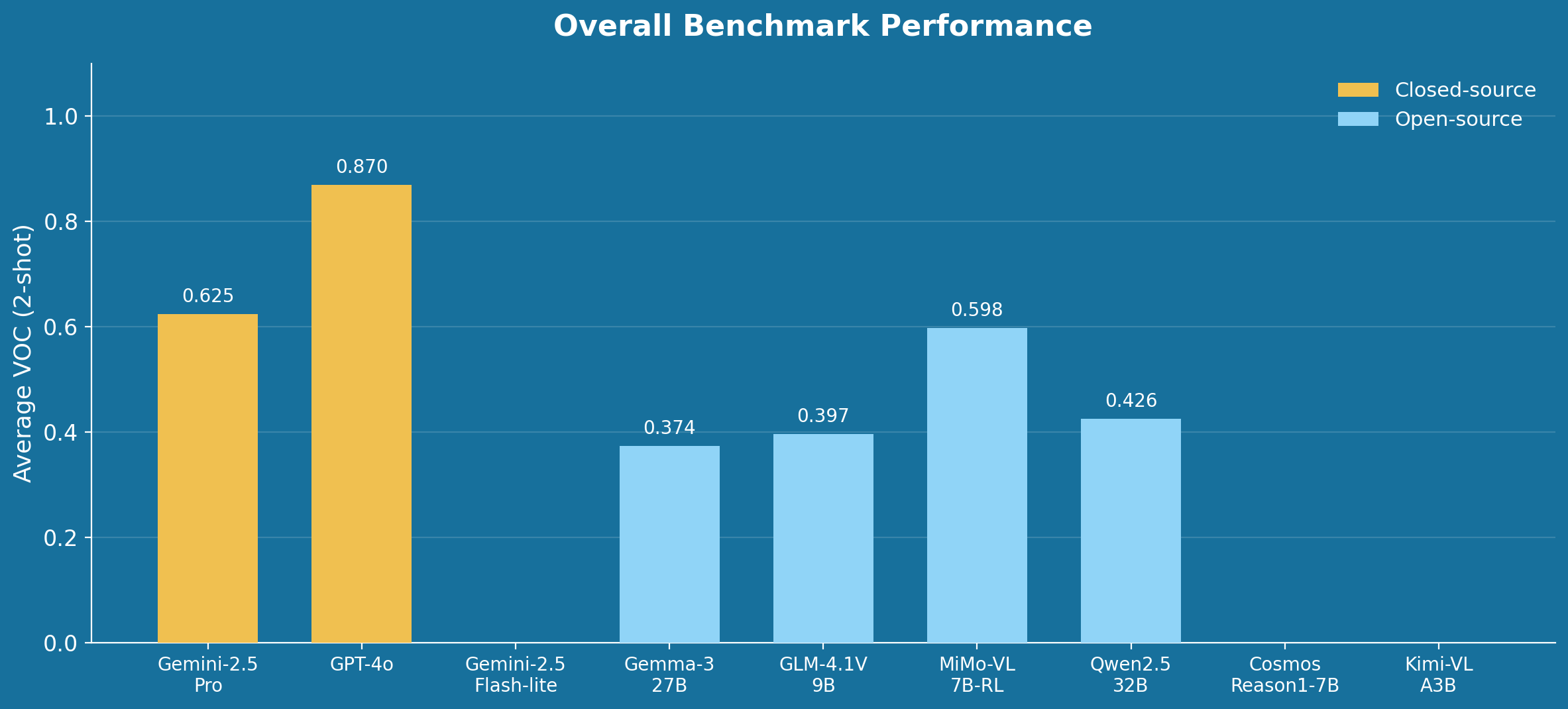
OpenGVL evaluates a broad range of both closed-source and open-source vision-language models. The closed-source baselines include Gemini-2.5-Pro, Gemini-2.5-Flash-lite, and GPT-4o. On the open-source side, the benchmark tests the Gemma-3 family (4B, 12B, 27B parameters), the Qwen2.5-VL family (3B, 7B, 32B parameters), and several reasoning-capable models including GLM-4.1V-9B, MiMo-VL-7B-RL, Cosmos-Reason1-7B, and Kimi-VL-A3B.
The central finding is stark: open-source model families significantly underperform their closed-source counterparts, achieving only approximately 70% of their performance on temporal progress prediction. This gap is consistent across datasets and task types, underscoring the current limitations of open-source VLMs in spatial and temporal reasoning tasks relevant to robotics.
Benchmark Results
The benchmark is constructed from four established robotics datasets: nyu_door, berkeley_mvp, cmu_stretch, and nyu_franka. For each dataset, 50 episodes are sampled with \(N = 15\) random frames per episode, shuffled for evaluation. Several consistent patterns emerge from the results:
On the nyu_door dataset, Gemini-2.5-Pro achieves a VOC of 0.9158 (zero-shot) and 0.9654 (two-shot), while the best open-source model, GLM-4.1V-9B, reaches only 0.6420 and 0.6540 respectively. Gemma-3-27B attains 0.6372 (zero-shot) and 0.8219 (two-shot), demonstrating meaningful improvement from few-shot conditioning. On the more challenging berkeley_mvp dataset, the gap widens further: Gemini-2.5-Pro scores 0.5626 / 0.6806, whereas Gemma-3-27B manages only 0.1427 / 0.1575 and Qwen2.5-32B reaches 0.2491 / 0.2426.
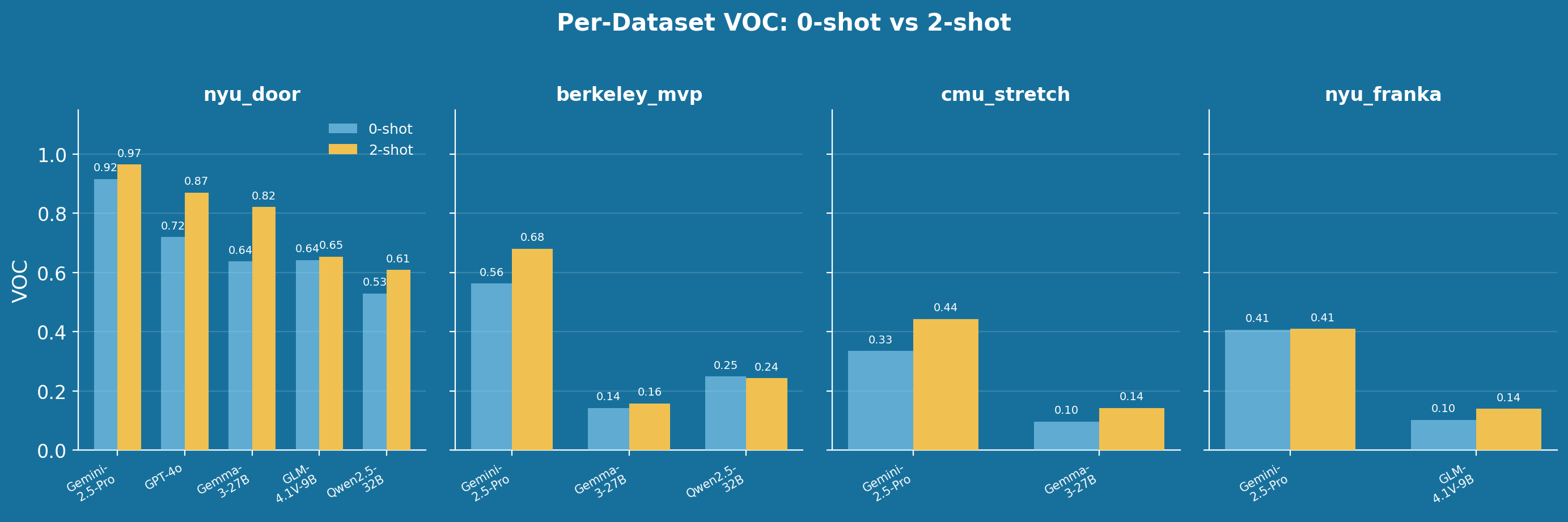
The results on cmu_stretch and nyu_franka follow the same trend. Gemini-2.5-Pro leads with 0.3348 / 0.4427 on cmu_stretch and 0.4065 / 0.4099 on nyu_franka, while the strongest open-source alternatives remain substantially behind. Within model families, scale consistently improves performance: larger variants outperform their smaller counterparts. Among reasoning-capable open-source models, MiMo-VL-7B-RL demonstrates the strongest results, while Kimi-VL-A3B falls short of expectations.
Beyond model evaluation, OpenGVL identifies three categories of dataset quality issues through its curation pipeline: task definition ambiguity, where instructions are unclear and completion metrics behave counterintuitively; labeling ambiguity, where task instructions are too vague to establish proper temporal relationships; and out-of-distribution episodes, where outlier trajectories exhibit irregular progress patterns that could confuse downstream model training.
Hidden Task
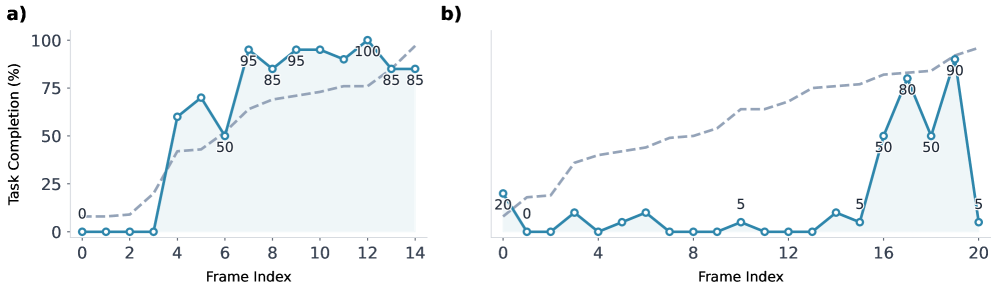
In addition to the public benchmarks, OpenGVL includes a hidden task evaluation designed to test model generalisation to real-world scenarios requiring long-horizon planning and dexterous manipulation. The hidden tasks involve last-mile electronic assembly with millimetre-level precision, executed by both a human operator and a 7-DOF robotic arm.
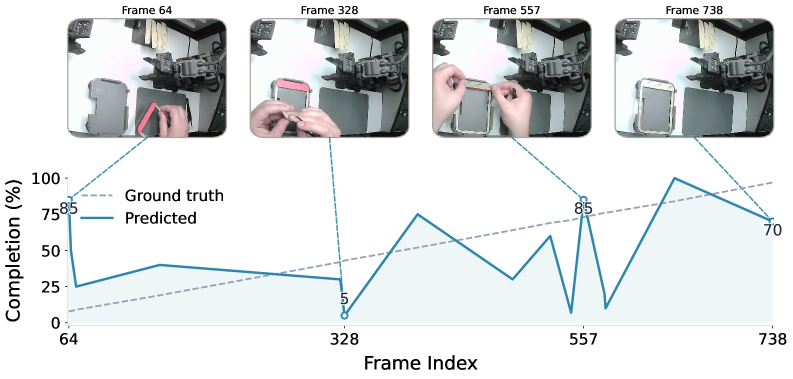
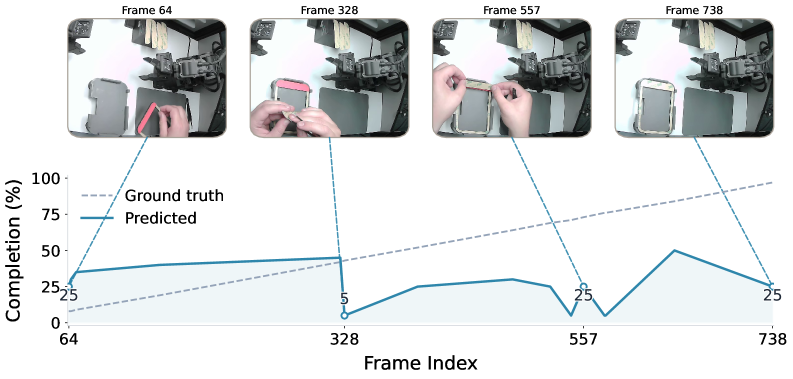
On these hidden tasks, the performance disparity between model classes becomes particularly pronounced. Gemini-2.5-Pro displays a monotonic upward trend in its predicted completion scores, correctly tracking the progression of the assembly task. In contrast, Gemma-3-27B demonstrates minimal predictive alignment, producing near-flat or noisy completion curves. These results highlight the difficulty that current open-source models face when confronted with fine-grained manipulation tasks outside their training distribution.
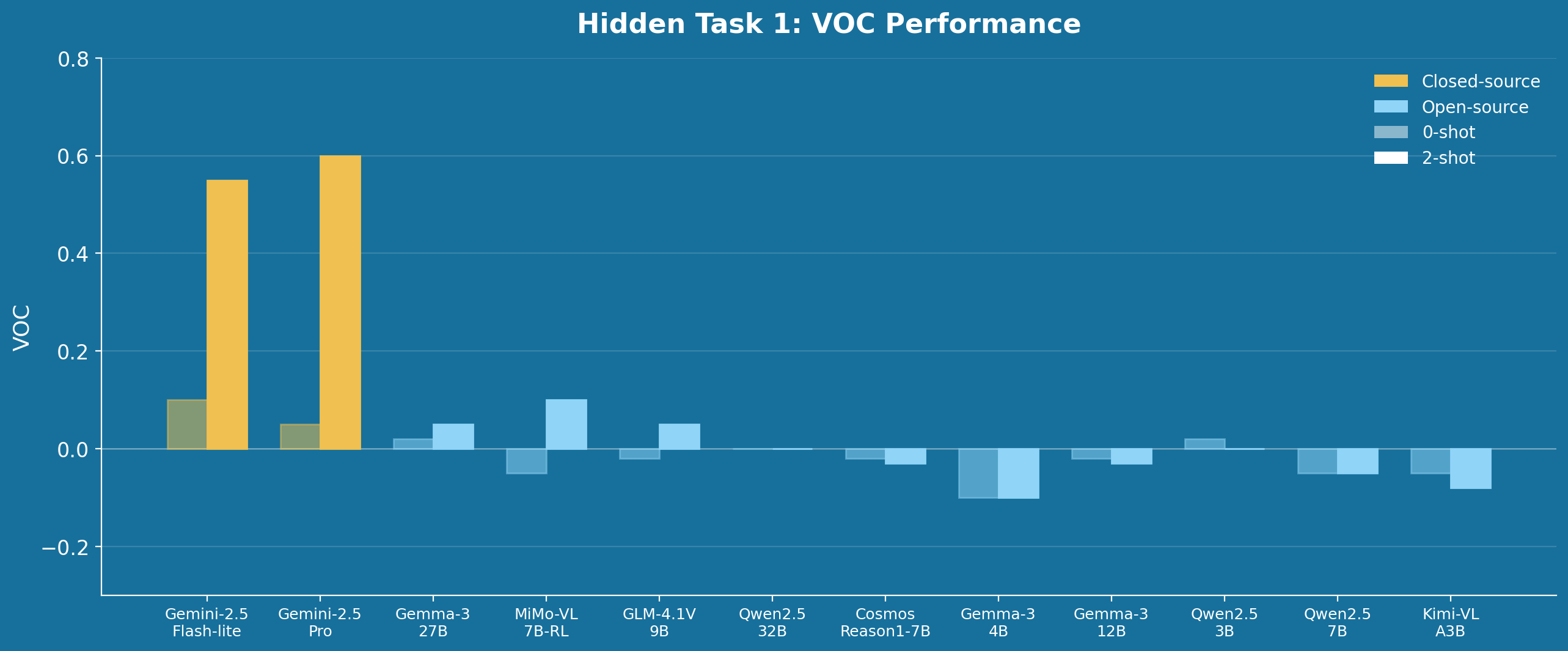
OpenGVL Leaderboard
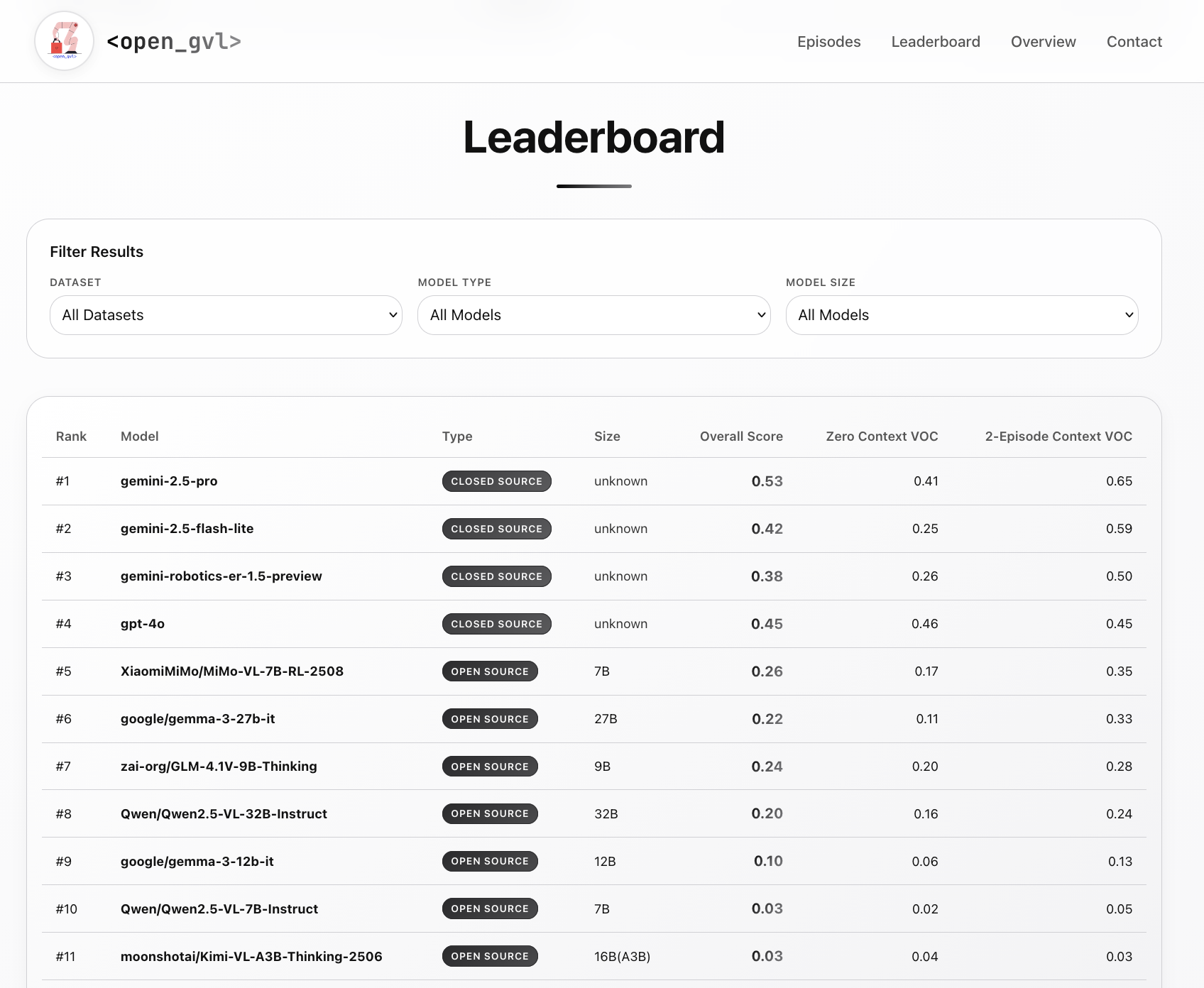
This work was presented at the Workshop on Making Sense of Data in Robotics at CoRL 2025. The leaderboard is available at huggingface.co/spaces/OpenGVL/OpenGVL while the complete codebase and benchmark are publicly available at github.com/budzianowski/opengvl. All models were evaluated at temperature \(T = 1.0\) using a single system prompt template, with trajectories sampled uniformly from expert demonstrations.
Citation
Please cite this work as:
@article{budzianowski2025opengvl,
author = {Budzianowski, Pawe{\l} and Wi{\'s}nios, Emilia and G{\'o}ral, Gracjan and Kulakov, Igor and Petrenko, Viktor and Walas, Krzysztof},
title = {OpenGVL -- Benchmarking Visual Temporal Progress for Data Curation},
journal = {Workshop on Making Sense of Data in Robotics at CoRL},
year = {2025},
note = {\url{https://arxiv.org/abs/2509.17321}},
}